
Développement de la partie matérielle
Le deuxième groupe d'étudiants à pour charge d'optimiser le coeur de l'application (Algorithme figure 3) en synthétisant un coprocesseur dédié (ray-tracing ASIC). Cet circuit dédié sera conçu en ciblant une technologie CMOS 1 micron de chez ES2, puis migré vers un ou plusieurs composants programmables de type FPGA (Flex8K de ALTERA).
La partie matérielle sera d'abord modélisée en VHDL comportemental avant d'être synthétisée. Les étudiants ont à leur disposition les outils de la société Compass sur station SUN, ainsi que l'outil de synthèse architecturale GAUT développé au laboratoire, dont la sortie respecte un format d'entrée de Compass [Martin 94]. Le composant cible retenu est un composant de la famille Flex 8000 de la société Altéra. Ce composant possède l'avantage d'être téléchargeable et d'intégrer toutes les ressources programmables nécessaires à l'architecture cible synthétisée. De plus la chaîne Compass fournit une bibliothèque pour ce composant.
Afin de valider la démarche globale, une carte (Figure 4) comprenant un Transputer et 2 FPGAs a par ailleurs été étudiée dans le cadre d'un projet de fin d'étude. Développée au format TRAM, elle peut être connectée à la carte mère B008 d'INMOS. La vue externe de l'ASIC coprocesseur est donnée figure 5. Les registres internes du coprocesseur accessibles par le Transputer dans sa zone mémoire sont explicités dans la figure 6.
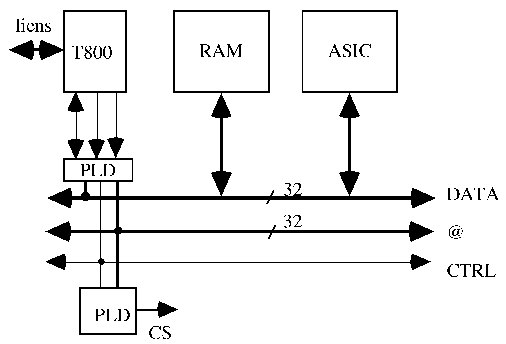
Figure 4: Carte au format TRAM développée. L'ASIC est en fait composé
de deux FPGA ALTERA EPF8820 (8K portes utilisables) et EPF81500 (16K
portes)
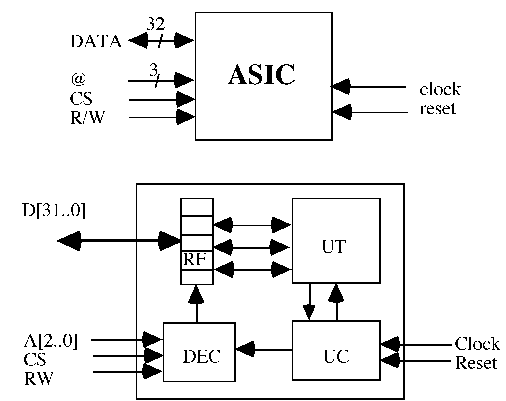
Figure 5: Vue externe et synoptique de l'ASIC

Figure 6: Mapping mémoire de l'ASIC

Figure 7: Programme de gestion de l'ASIC sur le Transputer
Le coeur de l'algorithme (algorithme 3) consiste en un calcul d'intersection entre une droite (le rayon lancé) et une sphère symbolisant la scène à synthétiser. Il contient 17 additions/soustractions, 17 multiplications, 3 comparaisons et un calcul de racine carrée. En implémentant le coeur de l'algorithme sur un Transputer T800, il nécessite 466 cycles machines de 50ns. Son remplacement par un coprocesseur situé dans la zone mémoire du Transputer, ne nécessite plus que 3 accès mémoire de 150 ns. L'accélération ainsi obtenue est de 466*50/(3*150), soit environ 50. Une parallélisation utilisant plusieurs de ces cartes devrait permettre une accélération supplémentaire. Diverses optimisations sont effectués avant la spécification de l'ASIC pour aboutir à la représentation sous forme de graphe flot de données figure 8. Celles ci ne sont détaillées ici.