Nous présentons dans ce document deux outils ŕ but pédagogique dont l'objectif principal est d'illustrer le principe de fonctionnement d'une hiérarchie mémoire ŕ un ou plusieurs niveaux. La simulation d'une hiérarchie mémoire particuličre s'appuie sur une configuration mémoire mais aussi et surtout sur une exécution de programme. En effet, pour montrer le fonctionnement d'un systčme constitué de mémoires caches, il est nécessaire de se donner une application et d'observer comment le systčme met ŕ profit les caches afin d'exécuter l'application plus rapidement. Il est donc nécessaire de disposer d'un outil permettant d'extraire les accčs mémoires réalisés par le processeur lors de l'exécution de l'application. durant son exécution. Pour cela nous allons utiliser un simulateur de processeurs. Le simulateur de processeurs dont nous avons besoin est un outil simple permettant l'exécution d'une application écrite en assembleur et indiquant, pour chaque instruction, s'il y a, ou non, un accčs ŕ la mémoire. Si c'est le cas, alors le simulateur doit indiquer quel type d'accčs mémoire est réalisé (lecture d'une donnée, écriture d'une donnée, lecture d'une instruction) et ŕ quelle adresse.
Ce document illustre l'utilisation de deux simulateurs, le premier (JSimVEM) permet de simuler le comportement d'un processeur de type Von Neumann, le second (JSimCache) permet la simulation d'une hiéarchie mémoire. L'étude que nous allons mener porte sur une application simple de type calcul numérique, il s'agit du produit de matrices.
L'enseignement des architectures des processeurs est un aspect important de la formation des ingénieurs de la filičre Electronique et Informatique Industrielle de l'ENSSAT (Ecole Nationale Supérieure des Sciences Appliquées et de Technologie). Nous pensons que ces futurs ingénieurs seront, au cours de leur carričre, confrontés aux développements de codes sur des processeurs de type traitement du signal (DSP). Or, il est évident que dans ce contexte, les algorithmes ŕ implémenter sont toujours assujetis ŕ une contrainte de temps d'exécution qui conduit globalement ŕ ce que les développeurs soient amenés ŕ écrire, ou ŕ retoucher, le code assembleur ŕ hauteur de 80 % du code total de l'application. Partant de cette constatation, il est alors important que nos futurs ingénieurs aient des connaissances assez précises concernant les techniques qui sont mises en oeuvre dans les processeurs récents, techniques qui migrent petit ŕ petit vers les processeurs de traitement du signal.
Les étudiants abordent le thčme des architectures de processeurs en premičre année par une immersion en douceur via le modčle de processeur Von Neumann. L'évolution des processeurs est commentée et l'on montre, notamment, l'accroissement important de la complexité des jeux d'instructions. La famille des processeurs Intel sert de base ŕ l'illustration de cette évolution pour des raisons évidentes de notoriété de ce constructeur. Le concept de machine RISC (Reduced Instruction Set Computer) est ensuite présenté en montrant que l'évolution des jeux d'instructions a conduit ŕ une utilisation trčs disparate des instructions d'un processeur complexe et en indiquant que certaines instructions sont finalement trčs peu utilisées par les programmes classiques. La rčgle des 90-10 est énoncée, indiquant que le processeur passe 90 % de son temps ŕ exécuter seulement 10 % de son jeu d'instructions.
Vient ensuite la présentation du concept de fonctionnement ŕ la chaîne, appelé fonctionnement pipeline. Ce principe étant posé, on montre tout l'intéręt d'un tel fonctionnement et on insiste sur le fait que celui-ci n'est vraiment intéressant que dans le cas oů le pipeline est alimenté de façon permanente. On montre ensuite comment les processeurs implémentent ce concept en découpant le contrôleur d'exécution des instructions en étapes de base (classiquement, les étapes de Lecture d'Instruction, de Décodage d'Instruction, d'Exécution d'Instruction et de Rangement de Résultat).
Un autre point important concernant l'organisation mémoire est aussi traité. Il s'agit ici de montrer comment on peut tirer parti de la mise en place d'une hiérarchie mémoire afin d'augmenter les performances d'un systčme ŕ base de processeur. Le fonctionnement des mémoires caches est présenté sur une structure ŕ un seul niveau de hiérarchie. Les techniques classiques de remplacement de blocs (LRU, FIFO, Random), d'associativité, d'écriture des données (write back, write through) sont discutées. Une séance de travaux dirigés est consacrée ŕ l'étude sous l'aspect coűt et performances de la mise en place d'une hiérarchie mémoire. Lors de cette séance de travaux dirigés, les étudiants observent que l'étude de performances, pour une application complexe, est longue et fastidieuse. Une séance de travaux pratiques est ensuite planifiée afin que les étudiants manipulent un outil de simulation de mémoires caches. Il s'agit alors de reprendre l'étude effectuée en séance de travaux dirigés, mais en approfondissant l'ensemble des configurations de mémoire cache possible afin d'étudier les effets des paramčtres tels que : la taille des blocs, la politique de remplacement de blocs, la politique d'écriture dans le cache, l'associativité, etc.
La suite de ce document présente les deux outils qui seront manipulés pour cette séance de travaux pratiques. Nous présentons ensuite l'exemple du produit de matrices servant de base ŕ l'étude du systčme de mémoire cache.
Ce TP s'appuie donc sur deux outils :
le premier est un outil de simulation de processeurs Von Neumann : JSimVEM ;
le second est un outil de simulation de mémoires caches : JSimCache.
Ces deux outils étant développés sur le męme principe et sur les męmes objectifs, nous ne développons ci-dessous que la structure du simulateur de processeurs.
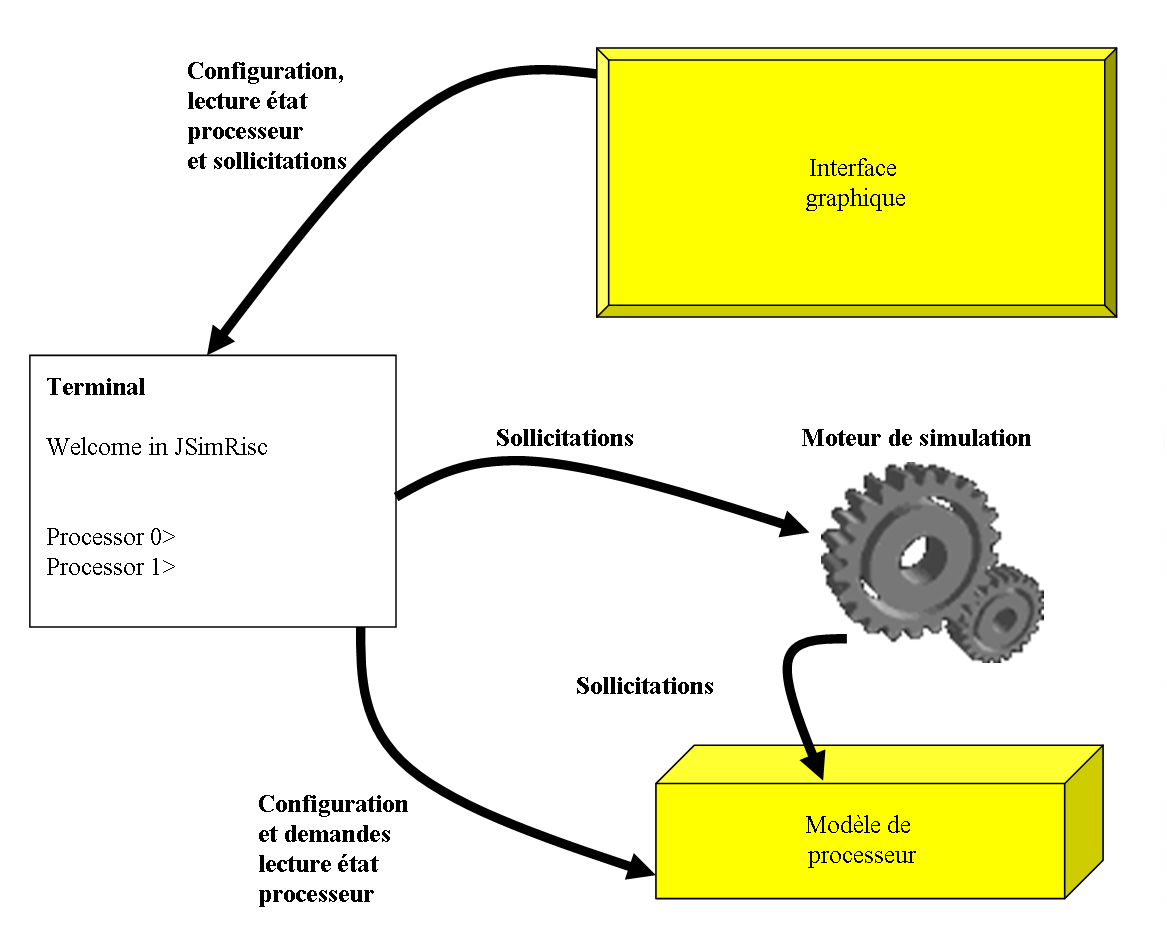
Lors de l'étude de conception du simulateur de processeurs, nous avons souhaité avoir une organisation facilitant le développement et la maintenance de l'outil. De plus, nous souhaitions pouvoir réutiliser des composants développés dans ce simulateur, pour d'autres outils de la męme famille. Nous avons aussi souhaité que ce simulateur de processeurs puisse ętre manipulé de deux maničres différentes : par l'intermédiaire d'un terminal, ou par l'intermédiaire d'une interface graphique conviviale.
Cet ensemble d'objectifs nous a conduit ŕ organiser notre outil en quatre niveaux (voir figure ci-dessous) :
Le premier niveau (celui du bas sur la figure) correspond au modčle du processeur. Il s'agit ici de reproduire le comportement d'un processeur simple (c'est-ŕ-dire de type Von Neumann). Un important travail de réflexion a été mené afin de rendre la modélisation du processeur la plus générique possible ;
Le second niveau (le centre de la figure) correspond ŕ un élément permettant de mettre en animation le modčle de processeur. C'est ce que nous appellons le moteur de simulation. Cet élément sollicite le processeur, par exemple en provoquant l'exécution d'un ou plusieurs cycles processeur.
Le troisčme niveau est représenté sur la gauche de la figure, il s'agit d'un terminal qui permet de configurer le processeur, puis qui joue ensuite le rôle d'intermédiaire entre l'utilisateur et le moteur de simulation. Le fonctionnement est ici trčs simple mais toutefois complet. L'ensemble des configurations peut ętre réalisé via la saisie de commandes au clavier. L'affichage de l'état du processeur s'effectue en mode texte par simple requęte saisie au clavier. Il faut admettre qu'une analyse fine du fonctionnement du processeur n'est pas aisée via ce terminal.
Le quatričme niveau est représenté sur le haut de la figure, il s'agit d'une interface graphique qui assure un abord convivial au simulateur. Via cette interface, l'ensemble des configurations est accessible. Celles-ci s'effectuent simplement par sélection de boutons, choix dans des listes de propositions, etc. Nous avons essayé de soigner particuličrement cette interface afin qu'elle soit la plus complčte possible et qu'elle permette une illustration claire du fonctionnement du processeur Von Neumann.
L'exemple que nous détaillons ici est le produit de matrices dont le code C est donné ci-dessous :
for (i = 0 ; i < N ; i++) {
for (j = 0 ; j < N ; j++) {
tmp = 0 ;
for (k = 0 ; k < N ; k++) {
tmp = tmp + A[i][k] * B[k][j] ;
}
C[i][j] = tmp;
}
}
Le simulateur de processeur que nous utilisons travaille sur du code assembleur. Nous donnons ci-dessous ce code assembleur pour ce modčle de processeur.
.data 0 .global a 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 7 8 8 8 8 8 8 8 8 .global b 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 4 4 4 4 4 4 4 4 5 5 5 5 5 5 5 5 6 6 6 6 6 6 6 6 7 7 7 7 7 7 7 7 8 8 8 8 8 8 8 8 .global c 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 .alias n 8 .alias n2 64 .program 100 li R1, a li R2, b li R3, c li R4, n li R10, n li R11, n2 .boucle1 li R5, n .boucle2 li R6, n li R7, 0 .boucle3 li R8, (R1) li R9, (R2) mult R9, R9, R8 add R7, R7, R9 add R1, R1, 1 add R2, R2, 1 sub R6, R6, 1 brnz R6, boucle3 si (R3), R7 add R3, R3, 1 sub R1, R1, R10 sub R5, R5, 1 brnz R5, boucle2 add R1, R1, R10 sub R2, R2, R11 sub R4, R4, 1 brnz R4, boucle1 exit .end
Ce code se décompose en deux parties :
la premičre partie (de .data ŕ .program) est constituée de déclarations dans la zone mémoire de données. Les matrices A, B et C sont positionnées (matrice A ŕ l'adresse 0, matrice B ŕ la suite de la matrice A, etc) et les labels correspondants sont déclarés. On notera aussi la déclaration d'alias permettant une écriture plus générique du code (.alias n 8 et .alias n2 64) ;
la seconde partie (de .program ŕ .end) de ce listing fournit le code assembleur du produit de matrices. Ce code assembleur est simplement composé des trois boucles imbriquées. Les registres R1, R2 et R3 sont utilisés en tant que pointeurs sur les éléments des matrices. Le calcul de l'élément Cij est effectué dans un registre puis envoyé en mémoire.
Pour simuler ce code, nous devons tout d'abord lancer l'outil JSimVEM.
Lancez le simulateur JSimVEM. La fenętre suivante doit alors apparaître.
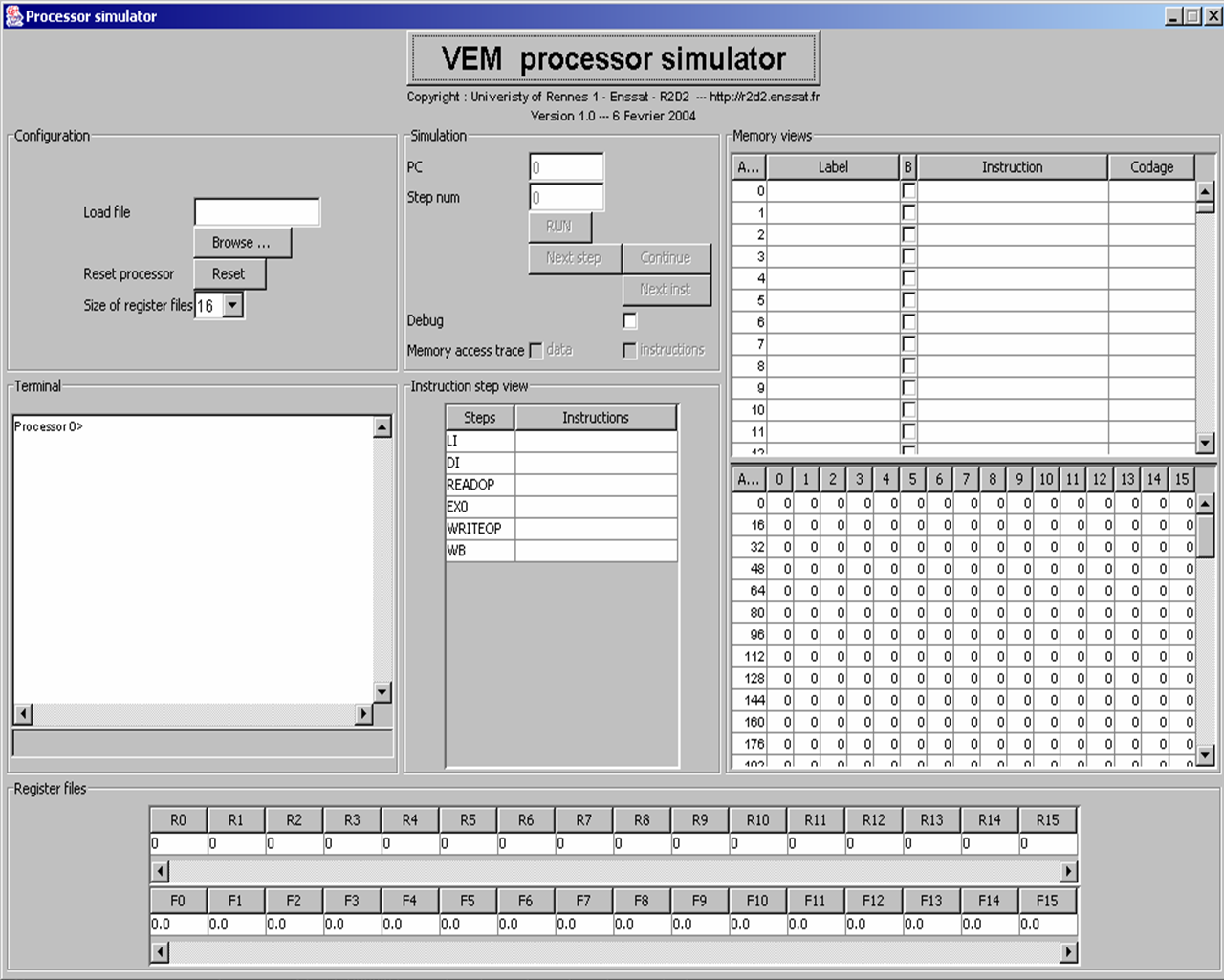
Cliquez sur le bouton Browse et sélectionnez le fichier ProdMat.s
Une fois le fichier chargé, vous devez voir apparaître le programme et les données dans la zone mémoire. La zone mémoire de programme doit se caller sur le code assembleur du produit de matrices : adresse 100. La zone mémoire de données doit se caller sur l'adresse de la matrice A, c'est-ŕ-dire l'adresse 0. A partir de l'adresse 64, on trouve la matrice B et enfin ŕ partir de l'adresse 128 se trouve la matrice C qui est initialisée ŕ 0.
Lancez ensuite la simulation du code en mode Run.
Une fois la simulation terminée, vous devez voir un nombre de Step num différent de 0. De męme, la zone de mémoire de
données correspondant ŕ la matrice C ne doit plus faire apparaître une suite de 0.
Vérifiez le résultat de l'exécution du code assembleur en vérifiant
le résultat de la matrice C. Le résultat que vous devez obtenir est celui-ci :
Adresses
128 8.0 16.0 24.0 32.0 40.0 48.0 56.0 64.0 16.0 32.0 48.0 64.0 80.0 96.0 112.0 128.0
144 24.0 48.0 72.0 96.0 120.0 144.0 168.0 192.0 32.0 64.0 96.0 128.0 160.0 192.0 224.0 256.0
160 40.0 80.0 120.0 160.0 200.0 240.0 280.0 320.0 48.0 96.0 144.0 192.0 240.0 288.0 336.0 384.0
176 56.0 112.0 168.0 224.0 280.0 336.0 392.0 448.0 64.0 128.0 192.0 256.0 320.0 384.0 448.0 512.0
Pour obtenir la liste des accčs mémoire réalisés par le processeur, vous devez valider les boutons radios Memory access trace. Vous pouvez extraire les accčs aux données et/ou les accčs au programme en cliquant sur les boutons data et/ou instructions. Si vous lancez une exécution (en mode pas ŕ pas ou en mode Run), alors que vous avez demandé une trace mémoire, vous obtiendrez un fichier ProdMat.s.mem dans le répertoire courant. La structure de ce fichier est la suivante. Chaque ligne du fichier correspond ŕ un accčs ŕ la mémoire de la part du processeur. Les requętes du processeur peuvent ętre de trois types différents, chaque type correspondant ŕ un code :
Réinitialisez le processeur, validez la trace mémoire pour les données et lancez une simulation. Une fois la simulation terminée, vérifiez que le nombre d'accčs total est bien correct. Vérifiez que la liste des accčs fournie est correcte.
Lancez le simulateur JSimCache. La fenętre suivante doit alors apparaître.
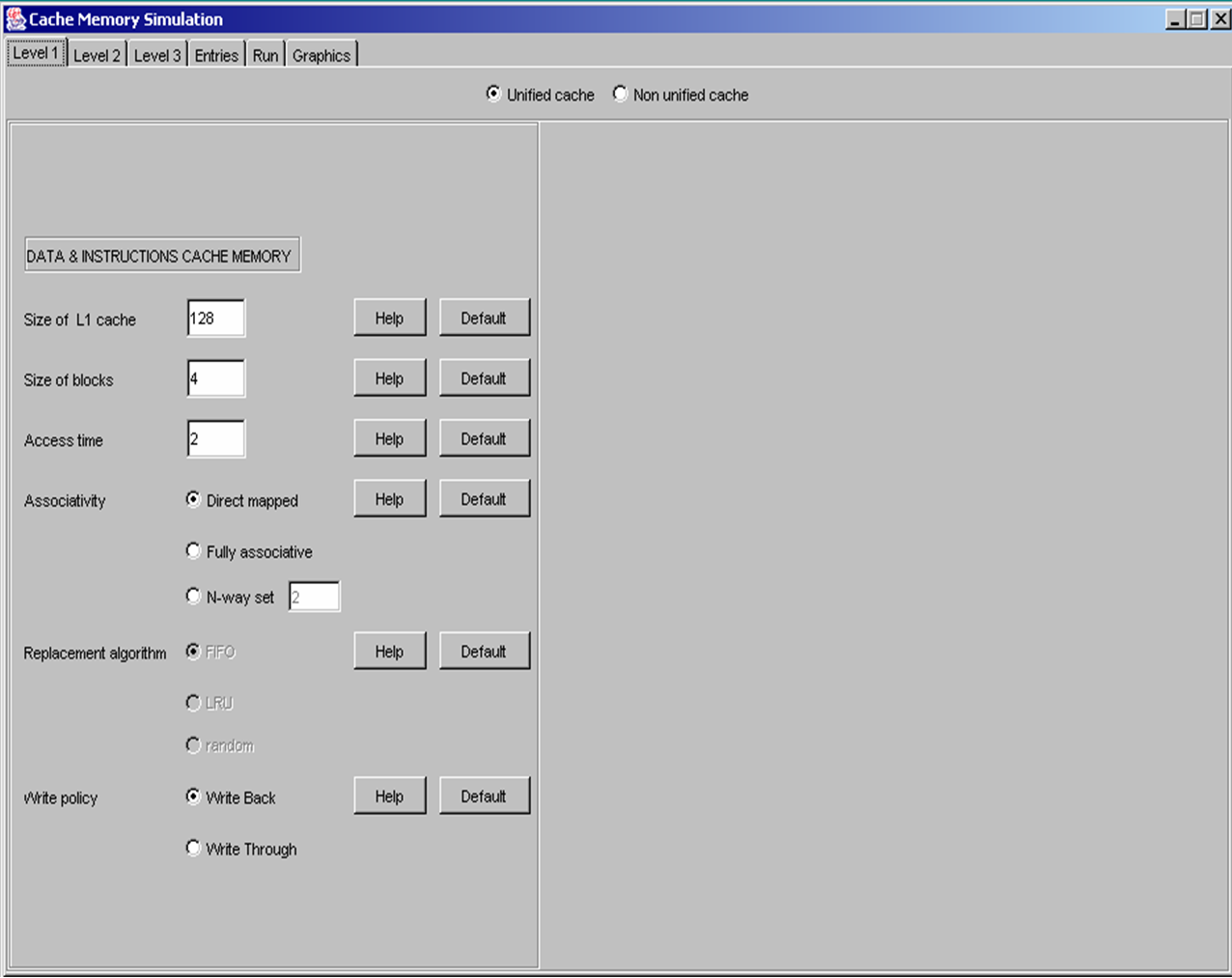
Vous devez d'abord configurer la hiérarchie mémoire. L'outil vous permet de simuler jusqu'ŕ trois niveaux mémoires caches plus une mémoire centrale. Par défaut, le systčme vous propose la simulation d'un systčme mémoire ayant un seul niveau de mémoire cache et une mémoire centrale. Configurez le premier niveau de mémoire cache, niveau Level 1, de façon ŕ avoir un cache de taille 128, des blocs de taille 16, une associativité complčte, une politique de remplacement de blocs de type LRU et enfin une politique d'écriture dans le cache du type write through.
Passez au second niveau de mémoire cache, onglet Level 2, et vérifiez que ce niveau n'est pas actif.
Passez au troisičme niveau de mémoire cache, onglet Level 3, et vérifiez que ce niveau n'est pas actif.
Remarque : Un niveau N de mémoire cache ne peut pas ętre actif si le niveau N-1 ne l'est pas.
Dans l'onglet Entries cliquez sur le bouton Load File et sélectionnez le fichier généré par l'outil JSimVEM. Indiquez aussi le temps d'accčs ŕ la mémoire centrale (en ns).
Lancez ensuite une simulation en passant ŕ l'onglet Run. Comme pour JSimVEM, vous pouvez exécuter la simulation en mode Run ou en mode pas ŕ pas.
Etude des accčs aux données :
Pour cette partie, validez uniquement la trace des accčs aux données dans le simulateur de processeurs
Von Neumann.
Reprenez la configuration de la séance de travaux dirigés (cache de taille 128 mots, blocs de taille 16 mots, associativité complčte, algorithme de type LRU, un seul niveau de cache) ;
Retrouvez les résultats de la séance de travaux dirigés, c'est-ŕ-dire 12 défauts de cache, et un temps total de 36 480 ns.
Etudiez l'impact des différentes politiques de remplacement de blocs (LRU, FIFO, Random). Vérifiez que la politique Random donne de bons résultats malgré ce que l'on pourrait en penser a priori ;
Analysez l'effet de l'associativité sur le nombre de défauts de cache. Vérifiez qu'une associativité faible (de l'ordre de 2 ou 4 voies) donne des résultats intéressants ;
Modifiez la taille des blocs et analysez l'évolution des défauts de cache. Tracez l'évolution du nombre de défauts pour une taille de blocs variant du minimum au maximum possible ;
Etude des accčs mémoire de l'ensemble du programme : accčs aux données et aux instructions :
Pour cette partie, validez la trace des accčs aux données et aux instructions
dans le simulateur de processeurs Von Neumann.
Effectuez des simulations avec un cache de niveau 1 unifié et non unifié.
Effectuez des simulations avec deux niveaux de cache.
JSimVEM a été développé avec pour principal objectif, l'illustration du cours d'architecture des processeurs de type Von Neumann. Le nom de ce simulateur correspond aux initiales des personnes qui ont défini l'architecture de ce que l'on appelle couramment les processeurs Von Neumann, ces trois personnes sont J.Von Neumann, J.P.Eckert et J.Mauchly.
Le processeur modélisé est un processeur Von Neumann dont le cycle d'exécution d'une instruction est décomposé en 6 étapes :
Le simulateur offre la possibilité de tracer les accčs mémoire afin, éventuellement, de procéder ŕ une simulation de mémoire cache. Le format retenu pour la trace des accčs mémoire est celui correspondant au simulateur de cache Dinero.
| 1) Instructions de transferts | |
| li, si | chargement/rangement mot vers/depuis des registres entiers |
| lf, sf | chargement/rangement mot vers/depuis des registres flottants |
| move | transfert entre registres |
| cmovz, cmovnz, cmovp, cmovp | transfert conditionnel entre registres |
| 2) Instructions arithmétiques et logiques | |
| add, addf | addition sur des entiers et flottants |
| sub, subf | soustraction sur des entiers et flottants |
| mult, multf | multiplication sur des entiers et flottants |
| and, nand | et, non et |
| or, nor, xor | ou, non ou, ou exclusif |
| 3) Instructions de contrôle | |
| br | branchement inconditionnel |
| brz, brnz | branchement si registre égal/non égal ŕ zéro |
| brp, brn | branchement si registre positif/négatif |
| nop | opération qui ne fait rien |
| exit | fin du programme |
JSimCache a été développé avec pour principal objectif l'illustration du concept de hiérarchie mémoire étudié dans le cours d'architecture des processeurs.
Ce simulateur a été développé dans le cadre du projet technologique de 3eme année par une étudiante de la filičre informatique de l'ENSSAT. Ce travail a débuté en septembre 2002 pour se terminer en juin 2003. Le développement a été réalisé en Java et s'appuie sur une modélisation de la hiérarchie mémoire, la mise en place d'un moteur de simulation et enfin l'ajout d'une interface graphique pour configurer et solliciter le systčme.