Pour aborder convenablement l'enseignement des architectures des processeurs récents, il est souhaitable
de proposer aux étudiants des séances de travaux pratiques illustrant simplement des mécanismes complexes.
La manipulation directe d'un processeur ne permet pas facilement de comprendre des fonctionnements
internes complexes. En effet, un bon nombre de techniques est implanté directement dans les étages pipeline
du processeur et il est délicat de suivre convenablement l'état du processeur cycle à cycle.
Pour faciliter la compréhension interne du processeur il est alors possible de s'appuyer
sur des outils de simulation de processeur. Ces outils basé, sur une l'émulation d'un processeur, permettent
de s'affranchir de la cible matérielle. Il existe plusieurs outils disponibles sur Internet qui offrent c
type de comportement.
Jusqu'à récemment , nous utilisions l'outil DlxView. L'interface graphique de cet outil ainsi que l'architecture
simulée issue du livre de Hennessy et Patterson est un bon support pour aider à la compréhension de
mécanismes complexes des récents processeurs.
Toutefois, il s'avère que certains mécanismes ne sont pas pris en charge par cet outil.
On citera par exemple, les mécanismes de prédiction de branchement, de branchement retardé, de disponibilité
d'instruction conditionnelle.
En connaissance des faiblesses de DlxView, nous avons entamé le développement, en interne, d'un outil de simulation
de processeur Risc permettant, entre autres, d'illustrer les
techniques précédemment citées. Cet outil, JSimRisc, a été utilisé pour
la première fois en travaux pratiques durant l'année universitaire 2003-2004.
L'outil nous a permis de couvrir les techniques qui étaient précédemment
illustrées par DlxView, mais nous a également permis de couvrir un plus large spectre de techniques.
L'enseignement des architectures des processeurs est un aspect important de la formation des ingénieurs de la filière Electronique et Informatique Industrielle de l'Enssat (Ecole Nationale Supérieure des Sciences Appliquées et de Technologie). Nous pensons que ces futurs ingénieurs seront, au cours de leur carrière, confrontés aux développements de codes sur des processeurs de type traitement du signal (DSP). Or, il est évident que dans ce contexte, les algorithmes à implémenter sont toujours assujetis à une contrainte de temps d'exécution qui conduit globalement à ce que les développeurs soient amenés à écrire ou à retoucher le code assembleur à hauteur de 80 % du code total de l'application. Partant de cette constatation, il est alors important que nos futurs ingénieurs aient des connaissances assez précises concernant les techniques qui sont mises en oeuvre dans les processeurs récents, techniques qui migrent petit à petit vers les processeurs de traitement du signal.
Les étudiants abordent le thème des architectures de processeurs par un premier module qui les immerge en douceur dans le domaine de l'architecture des processeurs. Ce premier contact est réalisé grace à la présentation du modèle de processeur Von Neumann. L'évolution des processeurs est soulignée en montrant, notamment, l'évolution importante de la complexité des jeux d'instructions. La famille des processeurs Intel sert de base à l'illustration de cette évolution pour des raisons évidentes de notoriété de ce constructeur. Le concept de machine Risc est ensuite présenté en montrant que l'évolution des jeux d'instructions a conduit à une utilisation très disparate des instructions d'un processeur complexe et en indiquant que certaines instructions sont finalement très peu utilisées par les programmes classiques. La règle des 90-10 est énoncée, indiquant que le processeur passe 90 % de son temps à exécuter seulement 10 % de son jeu d'instructions.
Vient ensuite la présentation du concept de fonctionnement à la chaîne, ou autrement dit de fonctionnement pipeline. Le principe de fonctionnement étant posé, on montre tout l'intérêt d'un tel fonctionnement et on insiste sur le fait qu'un fonctionnement de ce type n'est vraiment intéressant que dans le cas où le pipeline est alimenté de façon permanente. On montre ensuite comment les processeurs implémentent ce concept en découpant le contrôleur d'exécution des instructions en étapes de base (classiquement, les étapes de Lecture d'Instruction, de Décodage d'Instruction, d'Exécution d'Instruction et de Rangement de Résultat).
La suite de cet enseignement traite ensuite des problèmes qui sont engendrés par ce fonctionnement à la chaîne. On décortique le fonctionnement du processeur, et à chaque étape, on identifie le problème qui se pose, puis on montre comment les constructeurs contournent le problème. Les problèmes de dépendances de données sont pointés, de même que les problèmes liés à l'exécution des branchements, et plus particulièrement des branchements conditionnels. Les solutions proposées (les techniques de renommage de registres, de mise en place de buffers d'instructions, d'exécution dans le désordre, de prédictions de branchement, etc) sont alors présentées et illustrées autant que faire se peut dans le cadre du cours et des séances de travaux dirigés.
Pour compléter ces illustrations, il nous est apparut important de confronter les étudiants à ces techniques. L'utilisation directe d'un processeur étant quelque peu délicate en raison de la difficulté à accéder à l'ensemble des étages pipelines à chaque cycle, cela nous a conduit à nous tourner vers un simulateur de processeur. Notre choix initial de simulateur a été guidé par le livre de Hennessy et Patterson. En effet, les auteurs de ce livre appuient leur discours sur une architecture virtuelle : l'architecture DLX et l'existance d'un simulateur de processeurs répondant à cette architecture à évidemment été un critère important pour notre choix. Nous avons donc choisi le simulateur DlxView.
Bien que très convivial et pédagogiquement bien conçu, le simulateur DlxView n'offre pas une couverture suffisante pour aborder des techniques telles que la prédiction de branchement par exemple. De même, ce simulateur ne permet pas d'évaluer le fonctionnement d'autres modèles architecturaux tels que le modèle VLIW (Very Long Instruction Word). Pour tenter de couvrir un plus large spectre des techniques avancées mises en oeuvre dans les processeurs, nous avons entamé le développement, en interne, d'outils. Dans le cadre de ce document, nous présentons uniquement l'outil JSimRisc qui étend DlxView à la prise en compte des techniques de prédictions de branchement. On trouvera sur le site http://r2d2.enssat.fr des informations relatives aux autres développements effectués ou en cours (simulateur de processeur VonNeumann : JSimVEM, simulateur de processeur VLIW : VPS, simulateur de mémoire cache JSimCache).
La suite de ce document présente l'infrastructure logicielle mise en place ainsi que l'organisation globale du système développé. Nous présentons ensuite une série d'exemples en partant à chaque fois de problèmes spécifiques liés au fonctionnement pipeline.
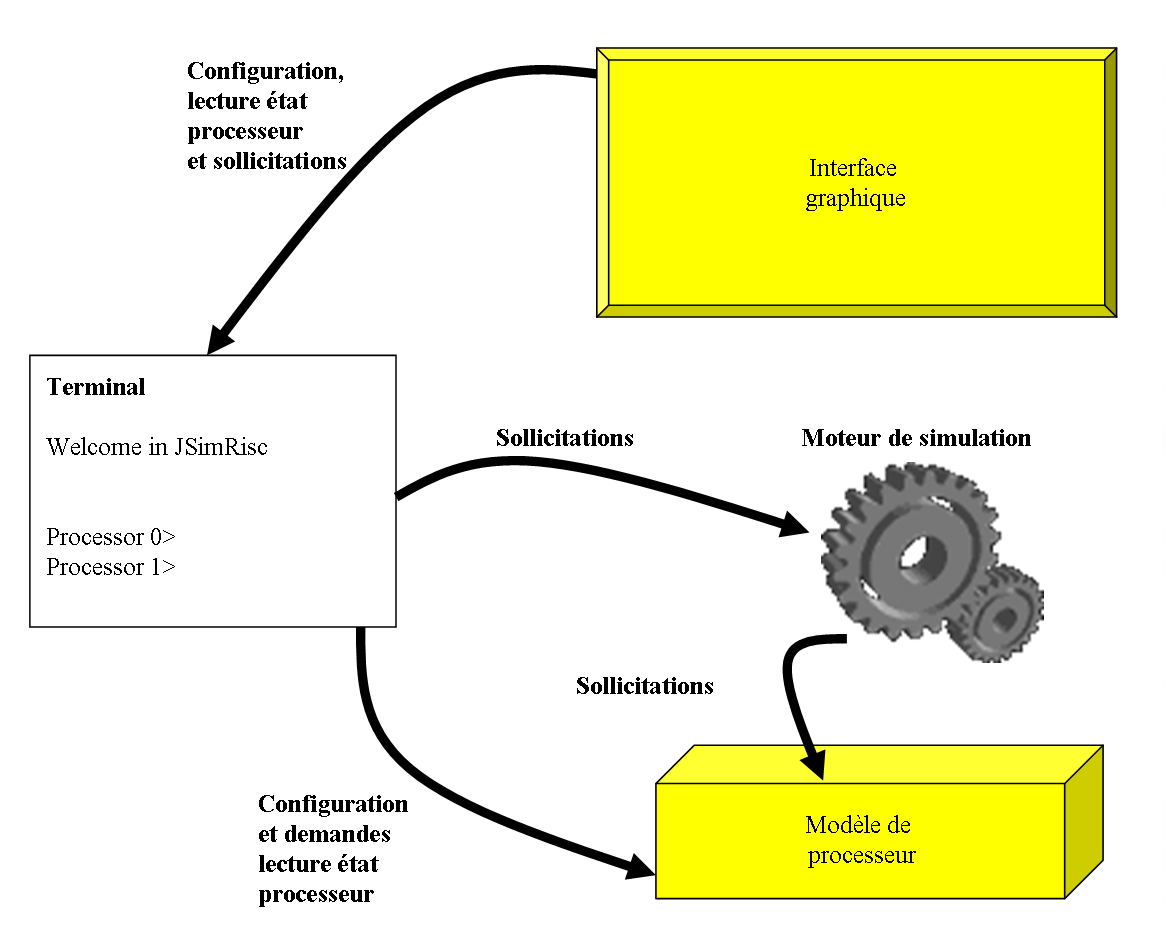
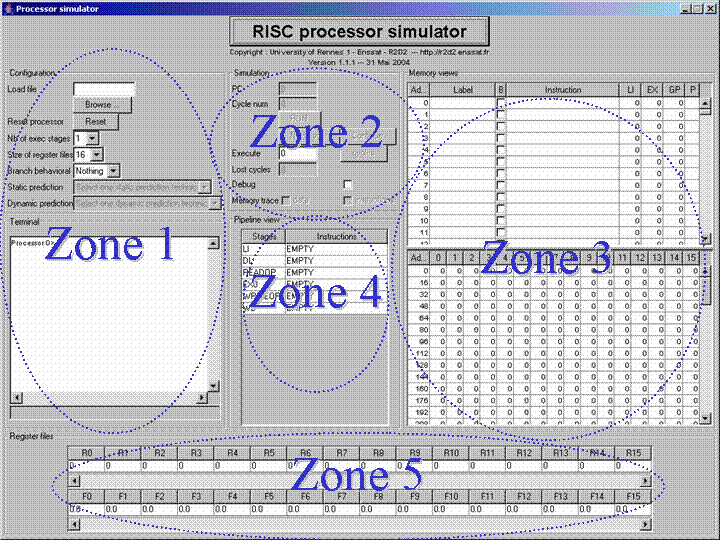
Lors de l'étude de conception de ce simulateur, nous avons souhaité avoir une organisation facilitant le développement et la maintenance de l'outil. De plus, nous souhaitions pouvoir réutiliser des composants développés dans ce simulateur, pour d'autres outils de la même famille. Nous avons aussi souhaité que ce simulateur de processeurs puisse être manipulé de deux manières différentes : par l'intermédiaire d'un terminal, ou par l'intermédiaire d'une interface graphique conviviale.
Cet ensemble d'objectifs nous a conduit à organiser notre outil en quatre niveaux (voir figure ci-dessous) :Le premier niveau (celui du bas sur la figure) correspond au modèle du processeur. Il s'agit ici de reproduire le comportement d'un processeur Risc pipeline. Un important travail de reflexion a été mené afin de rendre la modélisation du processeur la plus générique possible. En effet, nous souhaitions que notre simulateur nous permette d'étudier l'influence de l'allongement des pipelines par exemple, nous avons donc offert la possibilité de modifier, entre autre, la longueur de ceux-ci ;
Le second niveau (le centre de la figure) correspond à un élément permettant de mettre en animation le modèle de processeur. C'est ce que nous appellons le moteur de simulation. Cet élément sollicite le processeur, par exemple en provoquant l'exécution d'un ou plusieurs cycles processeur.
Le troisème niveau est représenté sur la gauche de la figure. Il s'agit d'un terminal qui permet de configurer le processeur, puis qui joue ensuite le rôle d'intermédiaire entre l'utilisateur et le moteur de simulation. Le fonctionnement est ici très simple mais toutefois complet. L'ensemble des configurations peut être réalisé via la saisie de commandes au clavier. L'affichage de l'état du processeur s'effectue en mode texte par simple requête saisie au clavier. Il faut admettre qu'une analyse fine du fonctionnement du processeur n'est pas aisée dans ce mode de fonctionnement.
Le quatrième niveau est représenté sur le haut de la figure, il s'agit d'une interface graphique qui assure un abord convivial du simulateur. Via cette interface, l'ensemble des configurations est accessible. Celles-ci s'effectuent simplement par sélection de boutons, choix dans des listes de propositions, etc. Nous avons essayé de soigner particulièrement cette interface afin qu'elle soit la plus complète possible et qu'elle permette une illustration claire des techniques liées au fonctionnement pipeline du processeur.
Les travaux de développement que nous avons entamés nous ont conduis à limiter, dans un premier temps, le nombre de techniques à couvrir. Nous souhaitions offrir au moins les mêmes fonctionnalités que DlxView tout en ayant la possibilité de faire évoluer le modèle du processeur.
Les techniques retenues dans la premiere version de notre simulateur sont :
la détection des dépendances de données et le traitement adéquat ;
la détection des instructions de branchement conditionnel et le traitement adéquat en fonction des différentes politiques (branchement retardé, prédiction statique, prédiction dynamique) ;
la prise en compte des instructions de transfert conditionnel.
Actuellement, le modèle de processeur ne permet pas d'illustrer certaines techniques. Ces limitations sont les suivantes :
pas de fonctionnement superscalaire du processeur ;
pas de fonctionnement VLIW du processeur ;
pas de renommage de registres ;
pas d'exécution du programme dans le désordre ;
Il est probable que ces limitations seront levées dans les versions futures de l'outil.
Avant de présenter les exemples, nous proposons un petit rappel de ce que l'on entend par fonctionnement pipeline d'un contrôleur de processeur. Il faut être conscient que l'introduction de ce mode de fonctionnement a été une avancée très importante pour les performances des processeurs. En effet, ce traitement à la chaîne des instructions permet d'augmenter la cadence à laquelle le processeur est en mesure de consommer le programme à exécuter.
Tous les processeurs récents (hormis peut être les processeurs enfouis) intègrent la notion de fonctionnement pipeline. L'intérêt principal du pipeline (ou traitement à la chaîne) réside dans la possibilité de traiter plusieurs instructions en même temps dans le processeur. Dans ce type de fonctionnement, les différentes instructions qui sont traitées par le processeur ne se trouvent pas à la même étape, elles sont chacune à un niveau de traitement différent.
On donne sur le schéma ci-dessous une représentation très générale du fonctionnement d'un pipeline. Une série d'instructions est représentée sur la gauche et l'on voit comment ces instructions vont traverser les différentes étapes.
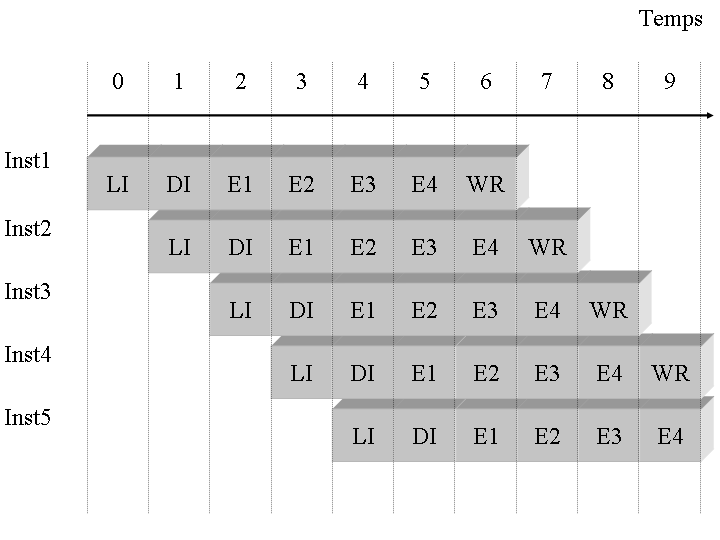
au cycle 0 : le processeur effectue la lecture de la première instruction à exécuter Inst1.
au cycle 1 : l'instruction Inst1 étant lue, elle est alors décodée. Pendant ce temps de décodage, plutôt que de laisser inactif le poste de travail chargé de lire les instructions, on lui demande de lire l'instruction suivante, soit l'instruction Inst2.
au cycle 2 : l'instruction Inst1 est décodée, elle est alors envoyée dans les étages d'exécution où il lui faudra plusieurs cycles pour se terminer. L'instruction Inst2 passe alors en phase de décodage. L'étage de lecture d'instruction étant alors libre, il effectue la lecture de l'instruction suivante, soit l'instruction Inst3.
au cycle 3 : l'instruction Inst1 poursuit son exécution dans les étages d'exécution du pipeline, cela signifie que l'unité fonctionnelle qui est chargée d'exécuter les instructions est, elle même, pipelinée. L'instruction Inst2 est alors envoyée dans les étages d'exécution, laissant ainsi la place à l'instruction Inst3 pour être décodée. Enfin, l'étage de lecture d'instruction étant libre, il peut charger l'instruction suivante, soit l'instruction Inst4.
au cycle 4 : les instructions Inst1 et Inst2 poursuivent leur chemin dans les étages d'exécution du pipeline. L'instruction Inst3 venant d'être décodée, elle peut elle aussi être prise en charge par les étages d'exécution, laissant du même coup la place à l'instruction Inst4 pour être décodée. Enfin, à cette étape, une cinquième instruction peut être chargée par l'étage de lecture d'instruction.
On arrête là la description du fonctionnement du pipeline du processeur. La suite du fonctionnement est identique. Notons tout de même que l'hypothèse qui est faite dans la représentation ci-dessus repose sur une indépendance complète des instructions les unes par rapport aux autres. Ce qui n'est évidemment pas toujours le cas.
Par rapport à un processeur Von Neumann classique (c'est-à-dire non pipeline), il est évident que la mise en place d'un traitement à la chaîne des instructions permet d'augmenter la fréquence d'horloge. En effet, ce traitement à la chaîne permet de scinder le traitement d'une instruction en plusieurs petites étapes et même si chaque instruction n'est pas traitée plus rapidement, le processeur consomme le programme beaucoup plus vite. Pour s'en convaincre, observons la figure ci-dessous.
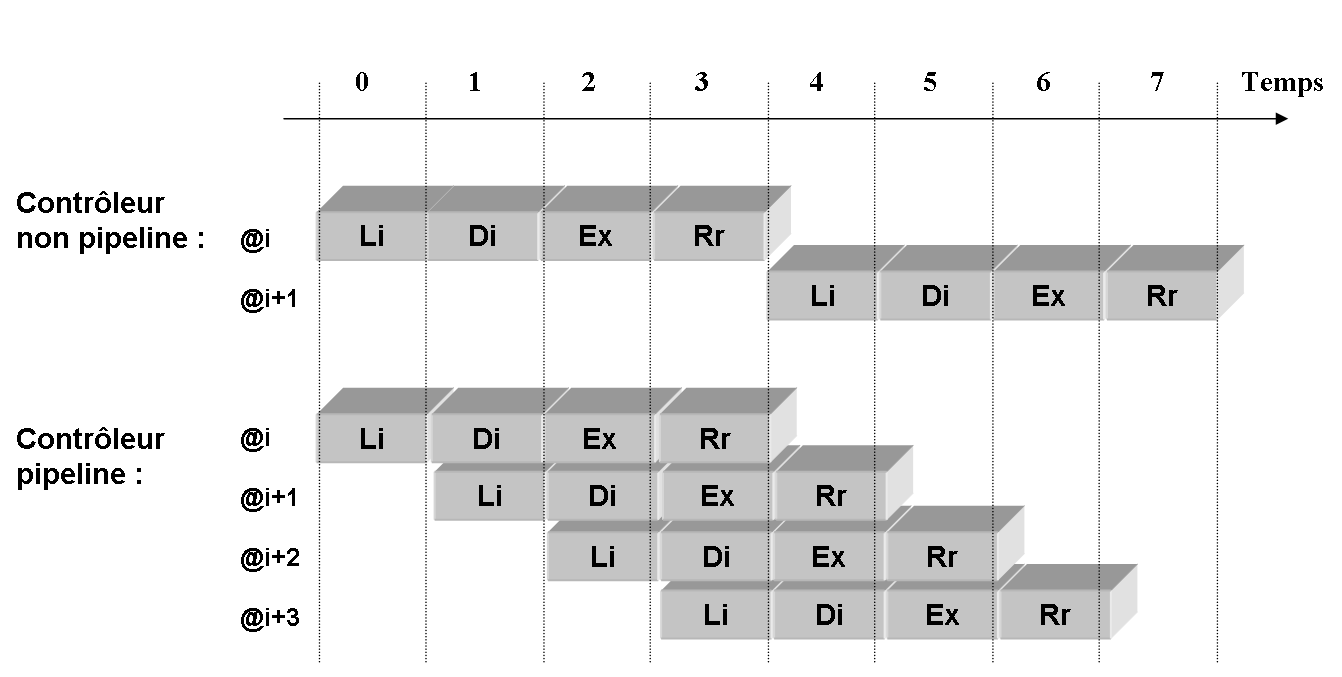
Comparons la vitesse à laquelle les deux contrôleurs ci-dessus consomment les instructions :
le premier contrôleur traite deux instructions en huit cycles : quatre cycles pour taiter la première instruction, et à nouveau quatre cycles pour traiter la seconde instruction ;
le second contrôleur traite les deux mêmes instructions en cinq cycles : quatre cycles pour traiter la première instruction, et à un cycle supplémentaire pour terminer la seconde instruction ;
Si l'on considère une suite infinie d'instructions entrant dans le pipeline, alors on constate que le processeur dont le contrôleur est pipeliné consomme le programme quatre fois plus vite que le processeur Von Neumann.
Les tendances actuelles dans les processeurs récents montrent que les pipelines s'allongent de façon très importante. Le processeur Pentium IV, par exemple, est découpé en 20 étages. Cette découpe du traitement d'une instruction en un grand nombre d'étages permet, notamment, au constructeur de pouvoir augmenter la fréquence d'horloge du processeur, ce qui est un argument commercial important.
Toutefois, il ne faut pas se voiler la face, cet allongement du pipeline d'exécution génère quelques difficultés quant à une utilisation efficace de celui-ci. Le code de haut niveau ci-dessous montre une dépendance de données (dépendance sur la donnée a qui va donner naissance à une dépendance de données au niveau assembleur.
a = b + c ;
d = a + e ;
Le code assmbleur généré par le compilateur sera alros le suivant
ADD R1, R2, R3 // R1 = R2 + R3
ADD R4, R1, R5 // R4 = R1 + R5
Il est clair que pour un processeur non pipeline, l'exécution de ces deux instructions ne pose aucun problème particulier. Par contre, dès lors que le processeur dispose d'un contrôleur pipeliné, alors peuvent survenir des problèmes qui engendrent une exécution incorrecte du programme.
Nous détaillons, dans les sections suivantes, les problèmes engendrés par le pipeline et nous expliquons les techniques proposées par les constructeurs.
Les applications classiques manipulent des données qui sont plus ou moins liées les unes aux autres. Cela se traduit par un code assembleur dont les instructions dépendent les unes des autres. Ces dépendances sont le fait des registres manipulés par les instructions. Prenons l'exemple du code ci-dessous :
ADD R1, R2, R3 // R1 = R2 + R3
ADD R4, R1, R5 // R4 = R1 + R5
Si aucun mécanisme particulier n'est mis en place pour détecter la dépendance créée par le registre R1 produit par la première instruction, puis lu par la seconde instruction, alors le fonctionnement du programme peut être incorrect.
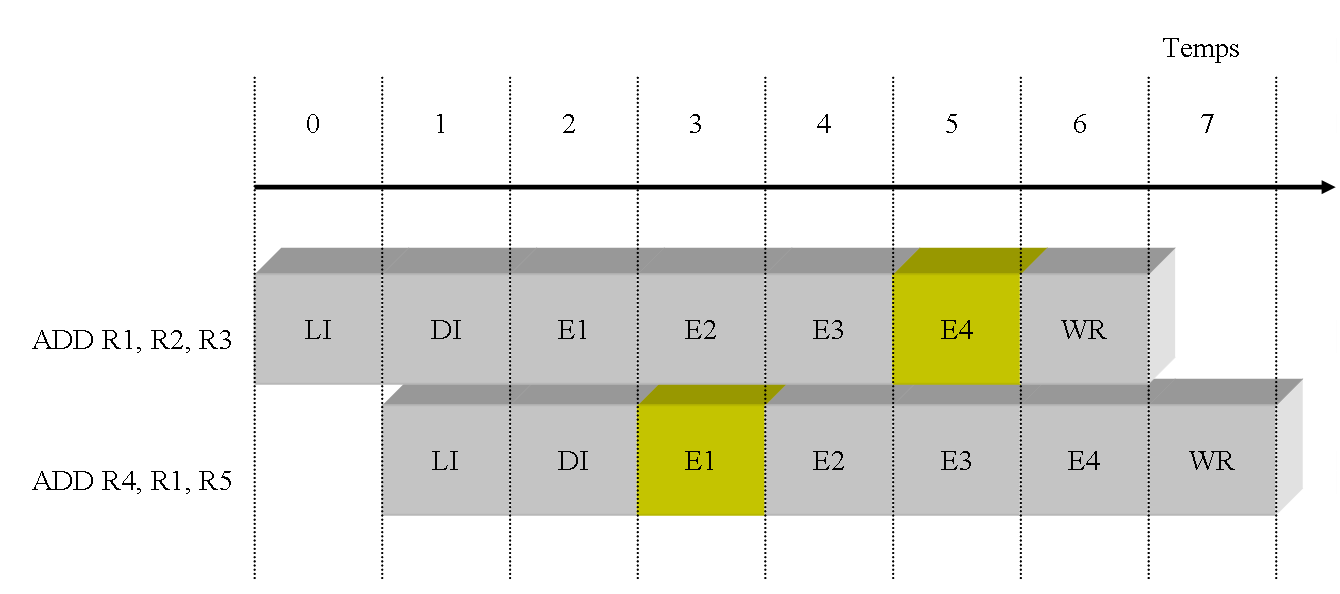
Sur la figure ci-dessus, on montre le déroulement de ces deux instructions dans le cas d'un processeur pipeliné sur 7 étages. La figure montre à quels instants les instructions vont manipuler l'opérande R1. On pose comme hypothèse que les opérandes sources sont lues au cycle E1 et que les opérandes destinations sont écrites au cycle E4. En imaginant que les valeurs des registres soient les suivantes :
la première instruction va écrire l'opérande destination R1 au cycle 5, c'est à dire la valeur 22 (12 + 10 = 22) ;
la seconde instruction va lire l'opérande source R1 au cycle 3. A ce cycle, R1 contient la valeur 2 ;
lorsque la seconde instruction sera terminée, le registre R1 contiendra la valeur 7 ((2 + 5 = 7) ;
La valeur contenue au cycle 3 dans le registre R1 ne peut pas être le résultat de l'instruction précédente, puisque celle-ci n'a pas encore écrit dans son opérande destination. On voit donc clairement, sur cet exemple simple, que le pipelinage du processeur provoque une exécution incorrecte du programme. Ce programme est pourtant bien correct, et n'importe quel développeur s'attend, en regardant ce bout de code, à ce que la seconde instruction effectue son calcul avec la valeur de R1 produite par la première instruction. Le résultat attendu dans le regitsre R4 est la valeur 27 ((12 + 10) + 5 = 27) et non la valeur 7 ((2 + 5) + 5 = 27)
Les techniques développées pour résoudre ce problème sont présentées ci-dessous. La première technique consiste simplement à stopper l'avancement des instructions dans le pipeline jusqu'à ce que toutes les opérandes sources de la seconde instruction soient disponibles. D'autres techniques proposent de casser cette dépendance de données soit par utilisation d'autres registres du processeur, soit par remise en cause de l'ordre d'exécution des instructions.
La solution la plus simple qui vient à l'esprit consiste à bloquer l'avancement de la seconde instruction pendant quelques cycles, puis à la débloquer afin que sa phase de lecture d'opérandes sources lui fournisse la bonne valeur pour R1. Dans ce cas, le pipeline devra être bloqué durant 3 cycles comme le montre la figure ci-dessous.
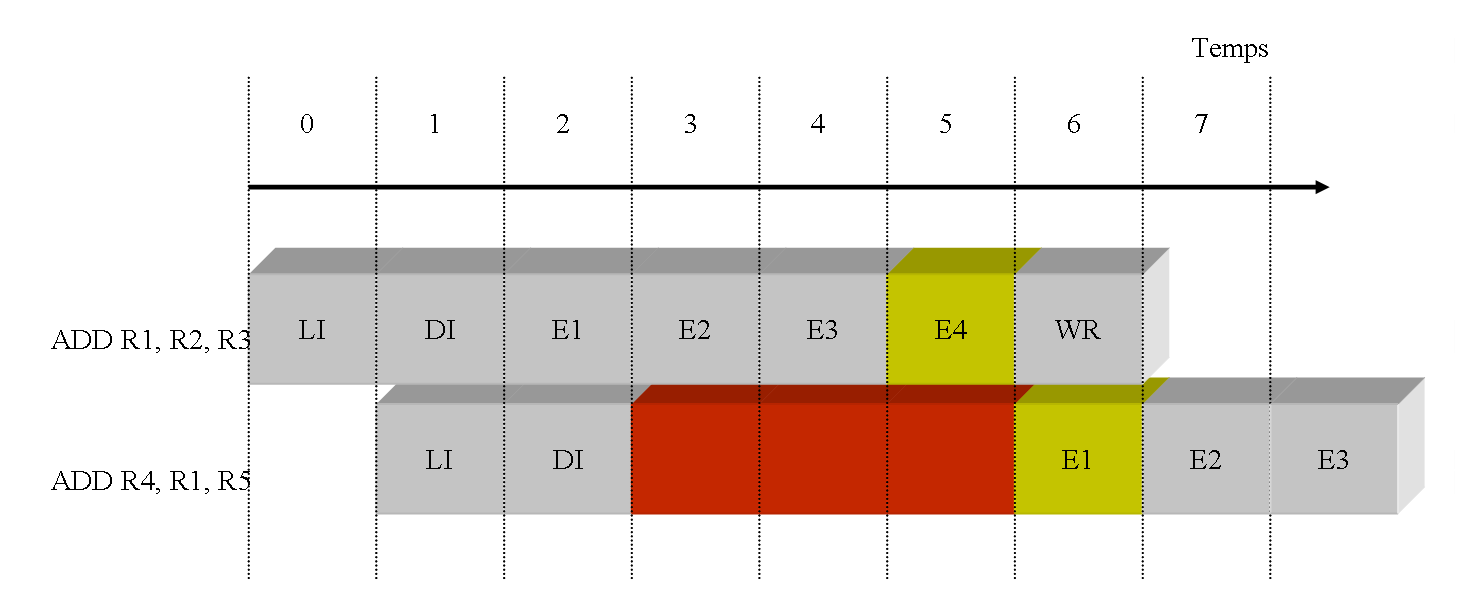
la première instruction produit le résultat 22 (12 + 10) dans le registre R1 au cycle 5 ;
la seconde instruction lit son opérande source R1 au cycle 6. La valeur lue est donc bien la valeur 22 ;
le résultat produit par la seconde instruction est alors la valeur attendue, soit la valeur 22 ;
Pour parvenir à un fonctionnement correct, le processeur doit posséder le moyen matériel de déterminer la dépendance entre les instructions et il doit prendre, dynamiquement, la décision de bloquer la seconde instruction dans l'étage DI. Ce bloquage provoque évidemment le blocage de tous les étages précédents du pipeline, mais laisse les étages suivants effectuer leur travail. Au cycle 5, la première instruction termine son exécution par l'écriture dans le registre résultat R1. Cette écriture dans R1 va provoquer le débloquage de la seconde instruction. Le résultat de l'exécution de ces 2 instructions par le processeur pipeline est alors correct.
Solution 2 : Renommage de registres
Solution 4 : Exécution dans le désordre
Le fonctionnement pipeline pose des problèmes de dépendance particuliers lorsque le processeur doit exécuter des instructions de branchement conditionnel. En effet, les instructions de branchement conditionnel ont la particularité d'avoir un comportement qui dépend d'une condition qui, dans certains cas, peut ne pas être disponible à l'instant souhaité. Prenons l'exemple du branchement conditionnel suivant :
@i SUB R1, R1, 1 // R1 = R1 - 1
@i+1 BRZ R1, @label // si R1 == 0 alors on saute a l'adresse label
Pour un processeur Von Neumann classique (non pipeline), l'exécution de l'instruction SUB va positionner une valeur dans le registre R1. Cette valeur sera ensuite lue par l'instruction de branchement conditionnel BRZ et utilisée pour décider si le saut doit être pris ou pas. L'instruction suivante qui sera lue par le processeur sera donc soit l'instruction de l'adresse @i+2 si la condition est fausse, soit l'instruction de l'adresse @label si la condition est vraie.
Dans le cas d'un processeur pipeliné, la difficulté tient à l'indisponibilité de la condition au moment où l'on doit décider de charger la prochaine instruction. Illustrons cela par la figure ci-dessous.
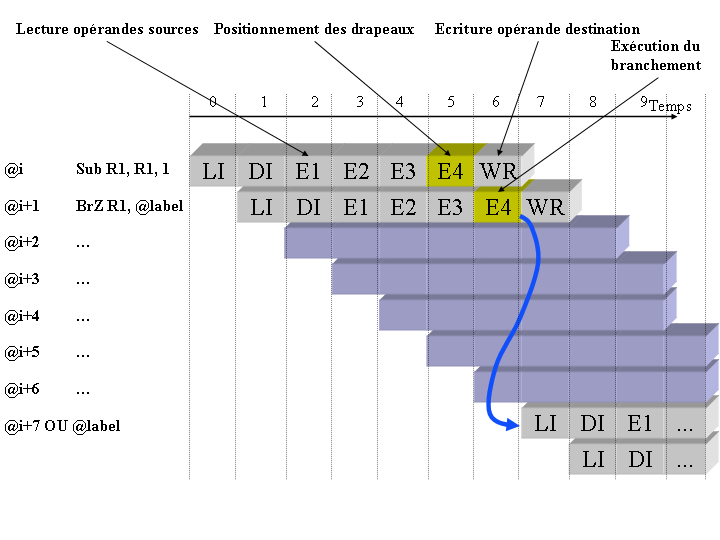
La première instruction va modifier le contenu du registre R1 au cycle 5. Ce qui permettra alors à la seconde instruction de savoir, au cycle 6, si le saut doit être exécuté ou non. Mais regardons ce qui s'est passé dans les cycles précédents et imaginons que le branchement attende la fin de l'exécution du SUB pour décider de son comportement.
au cycle 0 : le processeur effectue la lecture de la première instruction à exécuter, instruction Sub ;
au cycle 1 : l'instruction Sub étant lue, elle est alors décodée, l'instruction suivante est alors lue, instruction BrZ.
au cycle 2 : l'instruction Sub débute son exécution, l'instruction BrZ est alors décodée et une nouvelle instruction est alors lue, il s'agit alors forcément de l'instruction située à l'adresse i+2.
au cycle 3 : l'instruction Sub poursuit son exécution, l'instruction BrZ entre alors dans les étages d'exécution, l'instruction de l'adresse i+2 est alors décodée et tout naturellement, l'instruction de l'adresse i+3 est lue.
au cycle 4 : les instructions Sub et BrZ poursuivent leur chemin dans le pipeline, tandis que l'instruction de l'adresse i+4 entre dans ce même pipeline.
au cycle 5 : les instructions Sub et BrZ poursuivent leur chemin dans le pipeline, tandis que l'instruction de l'adresse i+5 entre dans ce même pipeline. A cette étape, l'instruction Sub effectue l'écriture de son opérande destination, c'est-à-dire que le registre R1 reçoit son résultat.
etc ...
Arrêtons là l'analyse et revenons sur le cycle 2. Ce cycle fait apparaître un problème. En effet, ne connaissant pas la valeur du registre R1 le branchement ne va pourvoir déterminer comment il doit se comporter.
Une solution simple pour résoudre le problème est d'appliquer la technique du blocage du pipeline jusqu'à ce que l'opérande source du branchement soit disponible. Cela nécessite donc de bloquer le pipeline durant cinq cycles, avant de pouvoir débloquer l'instruction de branchement. Cette solution est difficilement envisageable compte tenu du nombre d'instructions de branchement conditionnel présent dans les programmes classiques (environ une instruction sur cinq).
L'une des solutions possibles consiste à laisser le pipeline lire les instructions qui suivent le branchement et à les annuler s'il le faut. Dans le cas ci-dessus, on constate qu'entre le moment où le branchement entre dans le pipeline et le moment où l'on est capable de savoir comment exécuter ce branchement, 5 instructions ont été lues par le processeur. Au cycle 5, le registre R1 est produit, ce qui permet, au cycle 6 de connaître le comportement du branchement. A partir de là, deux cas de figures peuvent se présenter :
La condition de branchement est fausse (c'est à dire que le résultat de l'instruction Sub n'est pas nul), alors le processeur doit poursuivre son exécution sur les instructions des adresses i+2, i+3, i+4, i+5 etc etc. Dans ce cas, étant donné que ces instructions sont déjà rentrées dans le pipeline, on peut donc les laisser s'exécuter jusqu'au bout. Aucun problème particulier, pas de perte de cycles.
La condition de branchement est vraie (c'est à dire que le résultat de l'instruction Sub est nul), alors les instructions des adresses i+2, i+3, i+4, i+5, i+6 ne sont pas à exécuter, et le processeur doit poursuivre son exécution par les instructions se situant aux adresses label, label+1, label+2, etc etc. Dans ce cas, que fait-on des instructions qui sont entrées dans le pipeline alors qu'elles n'avaient rien à y faire ?
La solution technique mise en oeuvre pour annuler les instructions est une invalidation des écritures des opérandes destinations. Le fait de rendre l'écriture dans les registres résultats inactifs, transforme toutes ces instructions en instructions de type Nop. Cette solution, bien que donnant un fonctionnement correct, n'est pas satisfaisante car elle coûte cinq cycles processeur à chaque fois qu'un branchement conditionnel est pris. Ce problème est d'autant plus critique que le nombre de branchements dans les applications est globalement égal à 20 % (c'est-à-dire qu'une instruction sur cinq est un branchement). Dans ces conditions, il devient difficilement acceptable de perdre autant de cycles lors de l'exécution de ces applications.
La solution technique pour éviter de perdre trop de cycles processeur lorsqu'un branchement conditionnel est exécuté par le processeur, consiste à tenter de prédire comment va se comporter le branchement avant même que la condition ne soit connue (calculée).
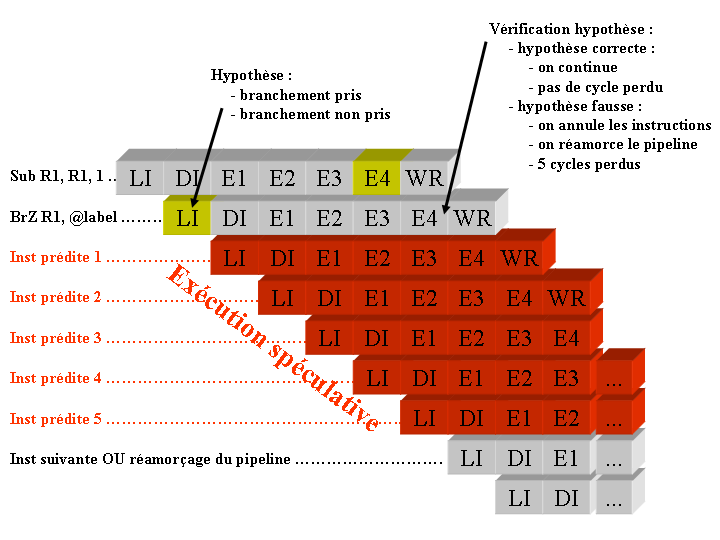
Lorsque l'instruction de branchement est lue par l'étage de lecture au cycle 1, le processeur va tenter de prédire son comportement. Le processeur va donc calculer une hypothèse concernant la suite des instructions à exécuter. Il va donc décider de :
Le cycle suivant, le processeur va donc faire entrer dans son pipeline des instructions dont il suppose l'exécution. On qualifie ces instructions de prédites, puisque l'on prédit leur exécution sans pour autant être sur qu'elles sont à exécuter. Lorsque l'instruction Sub termine son exécution, alors le processeur peut vérifier l'hypothèse qu'il avait faite. Deux situations peuvent alors se produire :
L'hypothèse calculée est correcte, c'est-à-dire que le processeur à décidé de continuer son exécution dans un certain sens (il a décidé de se brancher ou de ne pas se brancher), et ce choix se révèle le bon. Dans ce cas, le processeur poursuit son exécution sans perte de cycle ;
L'hypothèse calculée est fausse, c'est-à-dire que le processeur a décidé de continuer son exécution dans un certain sens, et ce choix se révèle incorrect. Dans ce cas, le processeur doit éliminer les instructions qui sont entrées dans le pipeline (puisqu'elles ne devaient pas être exécutées) et réamorcer son pipeline avec la bonne branche du programme.
Voilà simplement la technique de la prédiction de branchement à mettre en oeuvre et finalement, la problématique des branchements conditionnels est alors ramenée à un problème de calcul d'hypothèse sur le comportement de ces branchements. Si l'on est capable de prévoir le comportement de tous les branchements conditionnels sans jamais se tromper, alors aucun cycle processeur ne sera perdu à cause des branchements. Par contre, il est clair que si, pour chaque branchement conditionnel, l'hypothèse calculée se révèle fausse, alors le nombre de cycles perdus sera très important.
La question qui se pose alors est la suivante :
Comment prévoir le comportement d'un branchement ?
Plusieurs prédicteurs ont été développés. Les plus anciens prédicteurs étaient simples et peu coûteux à implémenter,
mais ils ont rapidement été remplacés par des prédicteurs plus complexes offrant de bien meilleures performances (on appelle
performance d'un prédicteur de branchement le taux de bonnes prédictions de celui-ci).
Il est relativement aisé d'observer que le nombre de cycles perdus en cas de mauvaise prédiction dépend
de la longueur du pipeline. Cette observation n'empêche pas pour autant les constructeurs à allonger le pipeline
de leurs processeurs. Il leur faut donc compenser l'augmentation du nombre de cycles perdus lors d'une mauvaise prédiction
par un taux de bonnes prédictions plus élevé.
Des pédicteurs avec des taux de bonnes prédictions voisins de 99%, et dans certains cas même supérieur,
ont alors été développés.
Les sections suivantes vont détailler les différentes techniques que l'on peut globalement classer en deux catégories qui sont les techniques statiques et dynamiques.
Ces techniques sont dites statiques parce qu'elles proposent une méthode globale à tous les branchements pour calculer l'hypothèse.
La première technique consiste à fixer une méthode (pour le calcul de l'hypothèse) unique pour tous les branchements conditionnels de l'application. Par exemple, à chaque fois que le processeur se trouve face à une instruction de branchement conditionnel, celui-ci pose comme hypothèse de prendre le branchement. Cette technique est évidemment peu souple et offre des performances (taux de bonnes prédictions) assez faibles. Elle a toutefois l'avantage d'être peu coûteuse.
Conscient des piètres performances de la première technique et sachant que le comportement moyen des branchements peut être différent d'une application à l'autre, certains constructeurs ont proposé un mécanisme permettant de positionner le sens de la prédiction. Par exemple, pour l'application 1, le processeur peut avoir une hypothèse telle que les branchements sont prédits pris, alors que pour une application 2, le processeur peut avoir l'hypothèse inverse (c'est-à-dire que tout branchement est prédit non pris). Le positionnement du sens de la prédiction est à la discrétion du développeur ou du compilateur. On peut dans ce cas s'appuyer sur une étude de profiling de l'application afin de positionner, de la manière la plus adéquate possible, le sens de la prédiction.
Des études sur le comportement des branchements ont montré que le comportement moyen de ceux-ci dépendait beaucoup de leur sens. La notion de sens des branchements permet de distinguer les branchements arrières et les branchements avants :
On parle de branchement arrière lorsque le processeur se branche à une adresse inférieure de l'adresse du branchement en question.
On parle de branchement avant lorsque le processeur se branche à une adresse supérieure de l'adresse du branchement en question.
Il a été montré que les branchements arrières ont plutôt tendance à être pris par le processeur. En effet, les branchements conditionneles arrières résultent très souvent de la compilation de boucles. Or la caractéristique principale d'une boucle est évidemment que les instructions situées dans la boucle vont être exécuter plusieurs fois. On donne ci-dessous le code de haut niveau d'une boucle exécutant N fois un calcul élémentaire.
for (i = 0 ; i < N ; i++) {
x[i] = u[i] + v[i];
}
La compilation va générer un code assembleur du type de celui donné ci-dessous.
Program LI R0, @U
LI R1, @V
LI R2, @X
LI R3, N
Boucle
LI R4, (R0)
LI R5, (R1)
ADD R6, R5, R4
LI (R2), R6
ADD R0, R0, 1
ADD R1, R1, 1
ADD R2, R2, 1
SUB R3, R3, 1
BRNZ R3, Boucle
End EXIT
Le comportement du branchement conditionnel arrière est presque toujours le même. En effet, ce branchement sera pris N fois, puis il sera non pris 1 fois.
Pour ce qui concerne les branchements avants, ils sont typiquement issus de la compilation d'un code ayant une structure si, alors, sinon telle que présentée dans le code ci-dessous. Or, il a été montré, même si c'est moins évident, qu'ils ont plutôt tendance à être non pris.
if (condition) else {
instructions ;
} else {
instructions ;
}
Compte tenu des résultats énoncés ci-dessus, il apparaît alors évident que si le processeur dispose de moyen pour détecter le sens du branchement, alors il pourra disposer de politiques de prédiction de branchement différentes, donc d'avoir un taux de bonnes prédictions meilleur que dans le cas d'une prédiction de branchement statique de base.
Les techniques de prédiction de branchement statique donnent des performances assez faibles et en tout cas pas suffisante dans le cas de pipelines très longs. Cela est notamment du au fait que ces techniques sont globales à tout ou partie des branchements d'une application. Elles ne tiennent donc pas du compte du comportement spécifique de chaque branchement. L'idée qui a alors été proposée consiste à tenter de conserver un historique du comportement de chaque branchement afin de mieux prévoir le comportement des prochaines exécutions de ces branchements. En effet, pour un branchement dont tous les comportements précédents ont conduit le processeur a effectuer un saut, il semble intéressant de conserver cette information et de l'exploiter lorsque ce branchement sera à nouveau a exécuter. Si le branchement a été, historiquement pris(respectivement non pris), alors il sera prédit comme devant être pris (respectivement non pris) une nouvelle fois.
La question qui se pose alors est de savoir comment on conserve cet historique. La première solution développé a consisté à attribuer un bit d'historique par branchement. Une seconde solution a ensuite été développé accordant 2 bits pour le stockage du comportement de chaque branchement.
Une table pour le stockage de cet historique des branchements est alors mise en place dans le processeur. Comme sa taille est forcement limitée et que tous les historiques de tous les branchements ne peuvent pas être conservés, alors le fonctionnement de cette table d'historique est assimilable à un cache. Ne sont conservés que les historiques des branchements les plus récemment exécutés. Cette table est ensuite utitlisée par le processeur afin de calculer l'hypothèse (la prédiction) et elle est mise à jour lorsque le branchement s'exécute (vérification hypothèse). La figure ci-dessous montre dans quels étages cette table est utilisée pour permettre une cohérence dans le processeur.
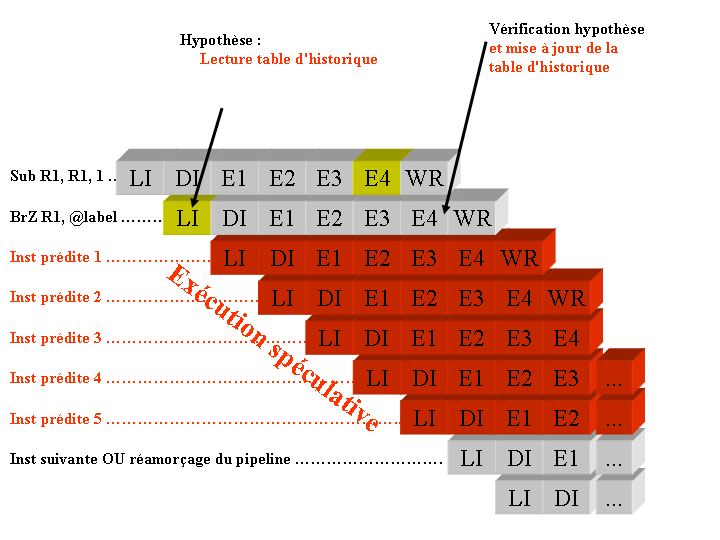
La prédiction de branchement dynamique à 1 bit met en oeuvre un seul bit pour stocker le comportement de chaque branchement. Ce bit mémorise alors un historique peu ancien indiquant simplement comment le branchement s'est comporté lors de l'exécution précédente.
Cette technique permet d'exploiter le caractère spécifique du comportement de chaque branchement conditionnel, mais l'historique conservé étant faible, ce prédicteur n'est pas très performant.
Les performances plutôt décevantes du prédicteur dynamique à 1 bit, ont amené les concepteurs a proposer un prédicteur conservant un historique plus important. Une solution mettant en oeuvre 2 bits pour stocker l'historique des branchements a alors été proposée. Les 2 bits de stockage de l'historique sont à nouveau utilisés pour calculer l'hypothèse. On représente ces valeurs possibles de ces 2 bits par une machine d'états dont les états sont les suivantes (voire aussi illustration dans la figure suivante) :
P : branchement historiquement pris ;
FP : branchement historiquement faiblement pris ;
NP : branchement historiquement non pris ;
FNP : branchement historiquement faiblement non pris ;
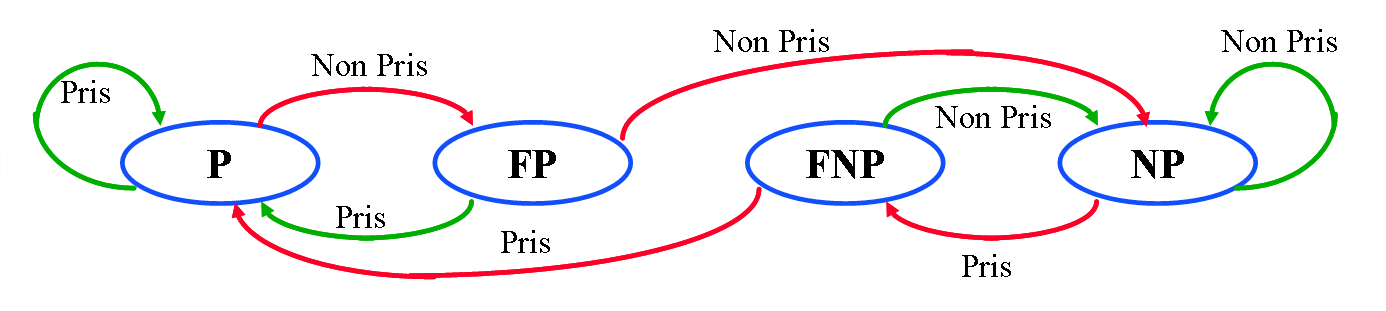
Les états vont permettre le calcul de la prédiction de branchement. Si la machine se trouve dans l'état P ou FP alors le branchement est prédit pris. Inversement, si la machine se trouve dans l'état NP ou FNP alors le branchement est prédit non pris.
Lors de l'exécution effective du branchement, le processeur vient faire une mise à jour de la machine d'états. Les mises à jour sont symbolisées par les changements d'états (flèches d'état à état sur la figure si-dessus).
Nous avons donné dans les sections précédentes, les solutions qui peuvent être mises en oeuvre dans le cas où le processeur doit exécuter des instructions de branchements conditionnels. Les constructeurs ont déployé des efforts importants pour fournir des prédicteurs de branchements efficaces. Il n'en reste pas moins que le problème est de plus en plus critique lorsque le pipeline du processeur s'allonge.
Il existe une autre voie pour limiter les risques de pertes de cycles dans les contrôleurs pipelines des processeurs dans le cas d'un branchement. Il s'agit tout simplement d'essayer de supprimer les instructions de branchements conditonnels. Cette solution qui peut sembler, a priori, utopique est toutefois réalisable par le biais du conditionnement de toutes les instructions du processeur. Considérons le code suivant :
if (condition) then {
instruction1 ;
instruction2 ;
} else {
instruction3 ;
instruction4 ;
}
La compilation de ce code va donner un listing assembleur du type de celui ci-dessous
...
BR condition, @then
else
instruction3 ;
instruction4 ;
BRA @suite
then
instruction1 ;
instruction2 ;
suite
...
...
Ce code fait nécessairement apparaître un branchement conditionnel dont le calcul d'hypothèse est assez délicat. L'idée consiste alors à proposer de supprimer ce branchement conditionnel au profit d'instructions dont l'exécution est rendue conditionnelle. Nous donnons ci-dessous un exemple de code assembleur avec utilisation d'instructions conditionnelles.
p1, p2 = eval (condition)
<p1> instruction1 ;
<p1> instruction2 ;
<p2> instruction3 ;
<p2> instruction4 ;
La première instruction de ce code permet une évaluation de la condition. Cette évaluation est utilisée pour positionner deux registres booléen spécifiques. Le premier registre est positionné à true si la condition est vraie, ou à false si la condition est fausse. Le second registre prend la valeur complémentaire.
Les instructions suivantes (partie the et else) sont ensuite alignées les unes à la suite des autres sans faire de saut. Les instructions circuleront donc dans le pipeline du processeur, mais seules deux de ces instructions auront s'exécuteront normalement, les deux autres auront le comportement d'instruction Nop. Les instructions qui s'exécuteront normalement sont celles dont le registre pi est vraie.
.data 96 .global a
1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3
4 4 4 4 4 4 4 4
5 5 5 5 5 5 5 5
6 6 6 6 6 6 6 6
7 7 7 7 7 7 7 7
8 8 8 8 8 8 8 8
.global b
1 1 1 1 1 1 1 1
2 2 2 2 2 2 2 2
3 3 3 3 3 3 3 3
4 4 4 4 4 4 4 4
5 5 5 5 5 5 5 5
6 6 6 6 6 6 6 6
7 7 7 7 7 7 7 7
8 8 8 8 8 8 8 8
.global c
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0
.global n
8
.global n2
64
.programm 100
li R1, a
li R2, b
li R3, c
li R4, (n)
li R10, (n)
li R11, (n2)
.boucle1
li R5, (n)
.boucle2
li R6, (n)
li R7, 0
.boucle3
li R8, (R1)
li R9, (R2)
mult R9, R9, R8
add R7, R7, R9
add R1, R1, 1
add R2, R2, 1
sub R6, R6, 1
brnz R6, boucle3
si (R3), R7
add R3, R3, 1
sub R1, R1, R10
sub R5, R5, 1
brnz R5, boucle2
add R1, R1, R10
sub R2, R2, R11
sub R4, R4, 1
brnz R4, boucle1
exit
.end
Cet outil complète, au travers de manipulations, la présentation de ces mécanismes sous forme magistrale et d'exercices. Nous proposons aux étudiants une application écrite naivement et nous leur proposons d'analyser le déroulement de cette application sur le processeur. L'analyse, en mode pas à pas, leur permet de comprendre où sont les problèmes. Nous leur proposons alors ensuite d'optimiser le code de l'application afin de répondre à une contrainte en nombre de cycles. Le gain que l'on attend en terme d'optimisation est supérieur à 50% (le nombre de cycles doit être plus que divisé par 2). Le déroulement des travaux pratiques, organisés sous une forme concours à l'optimisation maximale, montre que les étudiants confortent leur compréhension du fonctionnement d'un processeur pipeline.
JSimRisc a été développé avec pour principal objectif l'illustration du cours d'architecture des processeurs, dans lequel les mécanismes récents qui permettent d'augmenter les performances des processeurs sont presentés.
Ce simulateur s'inspire du simulateur DlxView basé sur l'architecture DLX presentée dans le livre de Hennessy et Patterson (Computer Architecture : a Quantitative Approach). Le développement a été réalisé en Java et s'appuie sur une modélisation d'un processeur RISC pipeline, la mise en place d'un moteur de simulation et enfin l'ajout d'une interface graphique pour configurer et solliciter le système.
Le processeur modélise est un processeur pipeline dont le nombre d'étages d'exécution est configurable. Le processeur contient un ensemble d'étages non configurable, il s'agit des étages :
Le simulateur offre la possibilité de tracer les accès mémoire afin, éventuellement, de procéder à une simulation de mémoire cache. Le format retenue pour la trace des accès mémoire est celui correspondant au simulateur de cache Dinero.
| 1) Instructions de transferts | |
| li, si | chargement/rangement mot vers/depuis des registres entiers |
| lf, sf | chargement/rangement mot vers/depuis des registres flottants |
| move | transfert entre registres |
| cmovz, cmovnz, cmovp, cmovp | transfert conditionnel entre registres |
| 2) Instructions arithmétiques et logiques | |
| add, addf | addition sur des entiers et flottants |
| sub, subf | soustraction sur des entiers et flottants |
| mult, multf | multiplication sur des entiers et flottants |
| and, nand | et, non et |
| or, nor, xor | ou, non ou, ou exclusif |
| 3) Instructions de contrôle | |
| br | branchement inconditionnel |
| brz, brnz | branchement si registre égal/non égal à zéro |
| brp, brn | branchement si registre positif/négatif |
| nop | opération qui ne fait rien |
| exit | fin du programme |